Exploiting the Signal-Leak Bias in Diffusion Models
Abstract
There is a bias in the inference pipeline of most diffusion models. This bias arises from a signal leak whose distribution deviates from the noise distribution, creating a discrepancy between training and inference processes. We demonstrate that this signal-leak bias is particularly significant when models are tuned to a specific style, causing sub-optimal style matching. Recent research tries to avoid the signal leakage during training. We instead show how we can exploit this signal-leak bias in existing diffusion models to allow more control over the generated images. This enables us to generate images with more varied brightness, and images that better match a desired style or color. By modeling the distribution of the signal leak in the spatial frequency and pixel domains, and including a signal leak in the initial latent, we generate images that better match expected results without any additional training.
Video Presentation
🔎 Research Highlights
- In the training of most diffusion models, data are never completely noised, creating a signal leakage and leading to discrepancies between training and inference processes.
- As a consequence of this signal leakage, the low-frequency / large-scale content of the generated images is mostly unchanged from the initial latents we start the generation process from, generating greyish images or images that do not match the desired style.
- Our research proposed to exploit this signal-leak bias at inference time to gain more control over generated images.
- We model the distribution of the signal leak present during training, to include a signal leak at inference time in the initial latents.
- ✨✨ No training required! ✨✨
Improving style-tuned models
Models tuned on specific styles often produce results that do not match the styles well. We argue that this is because of a discrepancy between training (contains a signal leak whose distribution differs from unit/standard multivariate Gaussian) and inference (no signal leak). We fix this discrepancy by modelling the signal leak present during training and including a signal leak at inference time too.
Model: sd-dreambooth-library/nasa-space-v2-768, with guidance_scale = 1
Prompt: "A very dark picture of the sky, Nasa style"
| Initial latents | Generated image (original) | + Signal Leak | Generated image (ours) |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
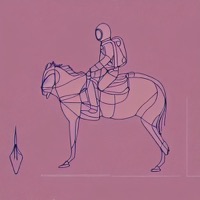
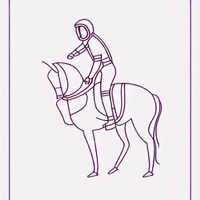
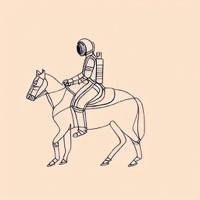
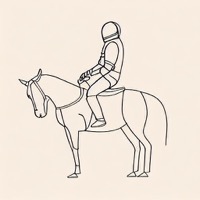
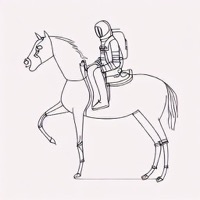
Model: CompVis/stable-diffusion-v1-4 + sd-concepts-library/line-art
Prompt: "An astronaut riding a horse in the style of
<line-art>"
| Initial latents | Generated image (original) | + Signal Leak | Generated image (ours) |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
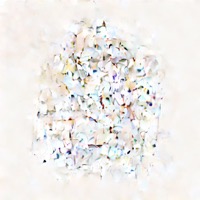 |
 |
Training-free style adaptation of Stable Diffusion
The same approach as the previous example can be used directly in the base diffusion model, instead of the model finetuned on a style. That is, we include a signal leak at inference time to bias the image generation towards the desired style.
Without our approach, the prompt alone is not sufficient enough to generate picture of the desired style. Complementing it with a signal leak of the style generates images that better match the desired output.
Model: stabilityai/stable-diffusion-2-1, with guidance_scale = 1
Prompt: "A very dark picture of the sky, taken by the Nasa."
| Initial latents | Generated image (original) | + Signal Leak | Generated image (ours) |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
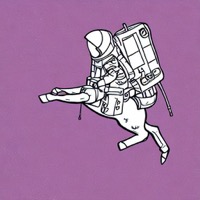
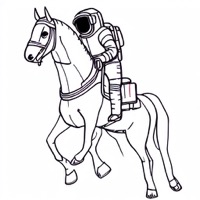
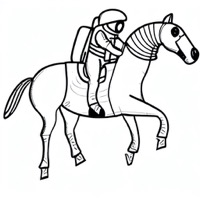
Model: CompVis/stable-diffusion-v1-4
Prompt: "An astronaut riding a horse, in the style of line art, pastel colors."
| Initial latents | Generated image (original) | + Signal Leak | Generated image (ours) |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
More diverse generated images
For natural images, the disrepency between training and inference distributiosn mostly lies in the frequency components: noised images during training still retain the low-frequency contents (large-scale patterns, main colors) of the original images, while the initial latents during inference always have medium low-frequency contents (e.g. greyish average color). Our approach generates less greyish images.
Model: stabilityai/stable-diffusion-2-1
Prompt: "An astronaut riding a horse"
| Initial latents | Generated image (original) | + Signal Leak | Generated image (ours) |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Control on the average color
It is also possible to manually set the low-frequency components of the signal leak, providing control on the low-frequency content of the generated image.
Model: stabilityai/stable-diffusion-2-1
Prompt: "An astronaut riding a horse"
| Channel | -2 | -1 | 0 | 1 | 2 |
|---|---|---|---|---|---|
| 0 |  |
 |
 |
 |
 |
| 1 |  |
 |
 |
 |
 |
| 2 |  |
 |
 |
 |
 |
| 3 |  |
 |
 |
 |
 |
Poster

License
The implementation is provided solely as part of the research publication "Exploiting the Signal-Leak Bias in Diffusion Models", only for academic non-commercial usage. Details can be found in the LICENSE file. If the License is not suitable for your business or project, please contact Largo.ai (info@largo.ai) and EPFL-TTO (info.tto@epfl.ch) for a full commercial license.
Citation
Please use the following BibTeX entry to cite our paper:
@InProceedings{Everaert_2024_WACV,
title = {{E}xploiting the {S}ignal-{L}eak {B}ias in {D}iffusion {M}odels},
author = {Everaert, Martin Nicolas and Fitsios, Athanasios and Bocchio, Marco and Arpa, Sami and S\"usstrunk, Sabine and Achanta, Radhakrishna},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
month = {January},
year = {2024},
pages = {4025-4034}
}