Diffusion in Style

Abstract
We present Diffusion in Style, a simple method to adapt Stable Diffusion to any desired style, using only a small set of target images. It is based on the key observation that the style of the images generated by Stable Diffusion is tied to the initial latent tensor. Not adapting this initial latent tensor to the style makes fine-tuning slow, expensive, and impractical, especially when only a few target style images are available. In contrast, fine-tuning is much easier if this initial latent tensor is also adapted. Our Diffusion in Style is orders of magnitude more sample-efficient and faster. It also generates more pleasing images than existing approaches, as shown qualitatively and with quantitative comparisons.
Video Presentation
Approach
We perform style adaptation of Stable Diffusion by fine-tuning the denoising U-Net with a style-specific noise distribution instead of the default white noise distribution. The parameters of the style-specific noise distribution are derived by computing statistics from a small set of images of the desired style. The same set of target-style images is also used for fine-tuning.

At inference time, we sample the initial latent tensor from the style-specific noise distribution and use the fine-tuned denoising U‑Net to iteratively denoise it.
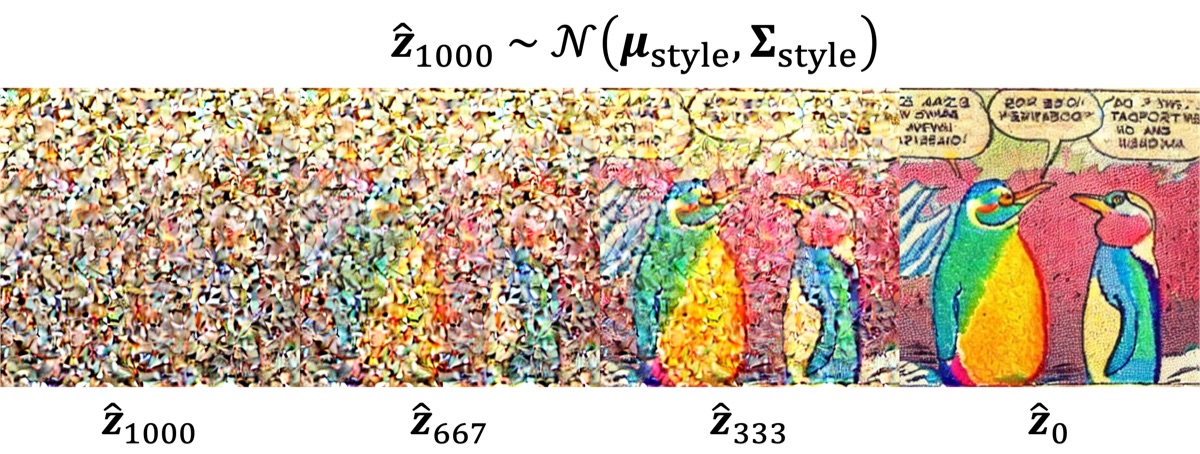
Poster

Citation
Please use the following BibTeX entry to cite our paper:
@InProceedings{Everaert_2023_ICCV,
title = {{D}iffusion in {S}tyle},
author = {Everaert, Martin Nicolas and Bocchio, Marco and Arpa, Sami and S\"usstrunk, Sabine and Achanta, Radhakrishna},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {2251-2261}
}License
This work corresponds to the patent filed under the reference number PCT/EP2023/065063. This work is under the license of Largo.ai, contact Largo.ai for any usage requests at info@largo.ai.