Abstract
Saliency prediction has made great strides over the past two decades, with current techniques modeling low-level information, such as color, intensity and size contrasts, and high-level ones, such as attention and gaze direction for entire objects. Despite this, these methods fail to account for the dissimilarity between objects, which affects human visual attention. In this paper, we introduce a detection-guided saliency prediction network that explicitly models the differences between multiple objects, such as their appearance and size dissimilarities. Our approach allows us to fuse our object dissimilarities with features extracted by any deep saliency prediction network. As evidenced by our experiments, this consistently boosts the accuracy of the baseline networks, enabling us to outperform the state-of-the-art models on three saliency benchmarks, namely SALICON, MIT300 and CAT2000.
Method Overview
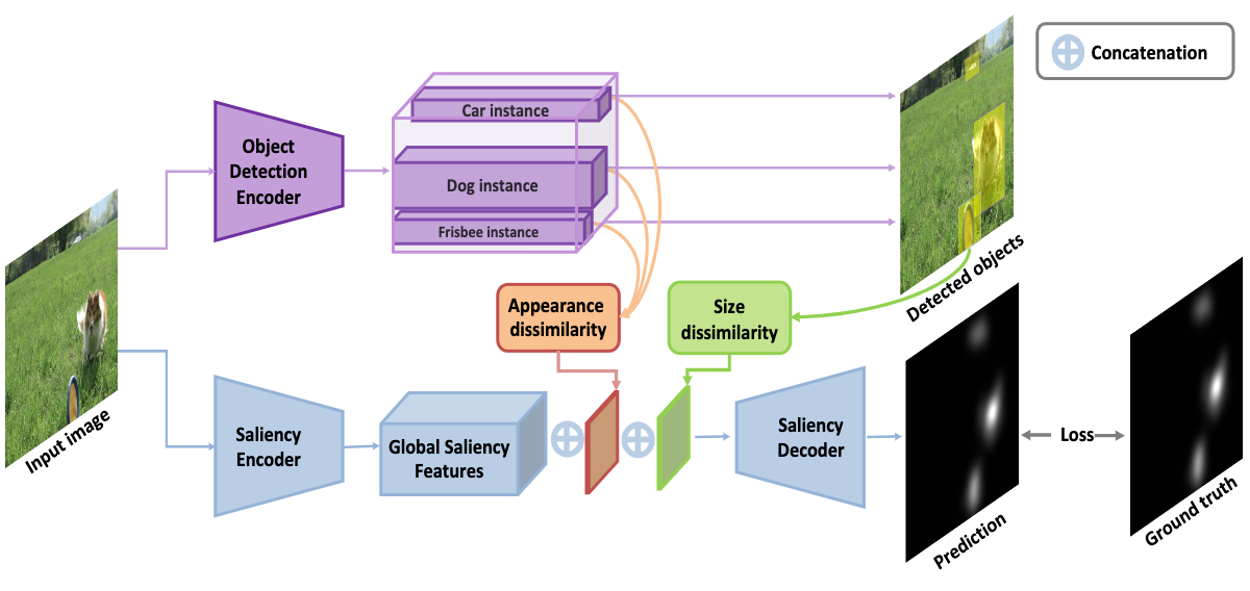
Overview of the proposed architecture. We use an object detector to extract object instances. We then pass on these object features to calculate appearance dissimilarity (shown in orange), which results in a dissimilarity score for each object instance. The object detection network also outputs a bounding box for each object, which we use to calculate the normalized object size dissimilarity (shown in green) for each detection. We then fuse (1) the encoded global saliency features resulting from the saliency encoder, (2) the object appearance dissimilarity features, and (3) the normalized object size dissimilarity features. We train our saliency decoder on this concatenated feature set. We supervise the training with a KLD loss between the predicted saliency map and the ground-truth one
Results

We show, from left to right, the input image, the corresponding ground truth, saliency maps from our model (Ours), the baseline results from DeepGazeII (Kümmerer et al., 2017), EML Net (Jia & Bruce, 2020), DINet (Yang et al., 2020), and SAM (Cornia et al., 2018), respectively. The results show how objects’ dissimilarity affects saliency. The top two rows show how object appearance dissimilarity affects saliency. For example, in the top row, the similarity of the objects from the same category (sheep) decreases their saliency, whereas the single occurrence of the person makes him more salient. Similarly, in the second row, the similarity of the objects from the same category (person) decreases their saliency. Whereas in the third row and the fourth row, the dissimilarity of the person with the surf-board and the skate-board makes him more salient, respectively. Note that the detection of the objects in our model facilitates this whereas the baseline DeepGazeII fails to do so. Similarly, in the fifth row, the similarity of the objects from the same category in the foreground (dogs) decreases their saliency compared to the single dog in the middle, whereas in the last row, the single bird is highly salient. Note that the baseline DeepGazeII model overestimates the saliency in the last row, whereas our model detects the bird and estimates it’s saliency close to the ground truth. (Best viewed on screen). 24
Qualitative Results on MIT1003

Qualitative Results on MIT1003 (Judd et al., 2009). We show, from left to right, the input image, the corresponding ground truth, saliency maps from our model (Ours), the baseline results from DeepGazeII (Kümmerer et al., 2017), EML Net (Jia & Bruce, 2020), DINet (Yang et al., 2020), and SAM (Cornia et al., 2018), respectively. The first row shows how both appearance and size dissimilarity affect saliency. For example, the similarity of the objects from the same category (person) decreases their saliency in the left and centre of the image, whereas in the right of the same image the man is more salient than the woman because of his size. In the second row, the single person is highly salient compared to the rocks that are not. Similarly, the similarity of the objects from the same category (duck) in the third row decreases their saliency, whereas in the fourth row, the single duck is more salient. The last row shows a typical failure case of our model. It is due to a detection failure (in this case the rock). Note that the baselines also fail on this image. (Best viewed on screen).
Bibtex
title={Modeling Object Dissimilarity for Deep Saliency Prediction},
author={Bahar Aydemir and Deblina Bhattacharjee and Tong Zhang and Seungryong Kim and Mathieu Salzmann and Sabine S{\"u}sstrunk},
journal={Transactions on Machine Learning Research},
year={2022},
url={https://openreview.net/forum?id=NmTMc3uD1G} }