Overview
In this supplementary material, we provide additional qualitative results and ablation studies for our TempSAL method. The document is structured as follows:
Section A : Additional Qualitative Results
Section B : Details on the Statistical Analysis
Section C : Equal Duration vs Equal Distribution
Section D : Results of the Slicing Alternatives
Section E : The Number of Time Slices
Section F : Approximation of Fixation Timestamps
A. Additional Qualitative Results
We provide additional qualitative results for our model on the SALICON validation dataset. We use an animated image format due to the temporal nature of our results. Best viewed on screen.
Input image
Ground truth
TempSAL



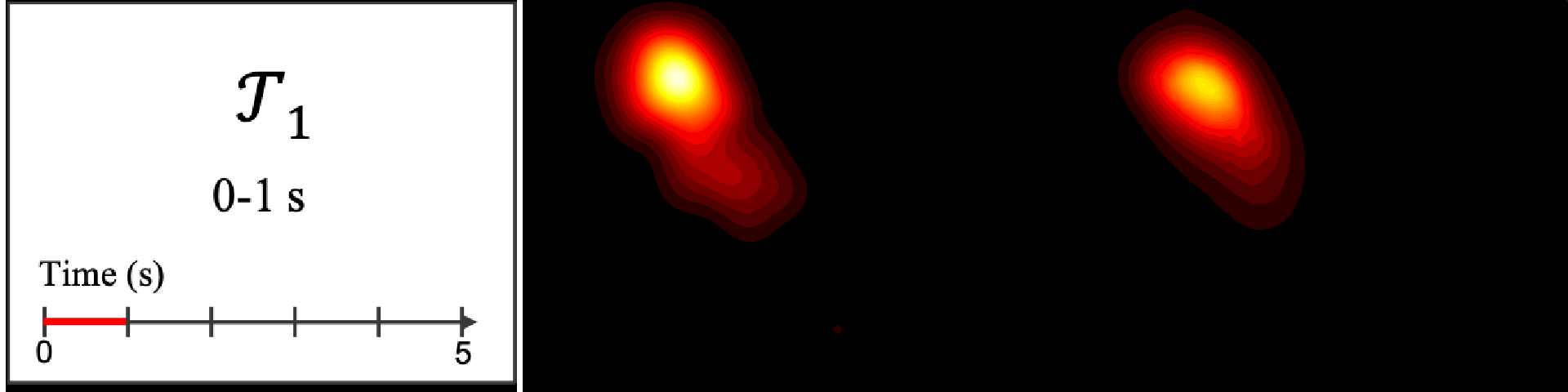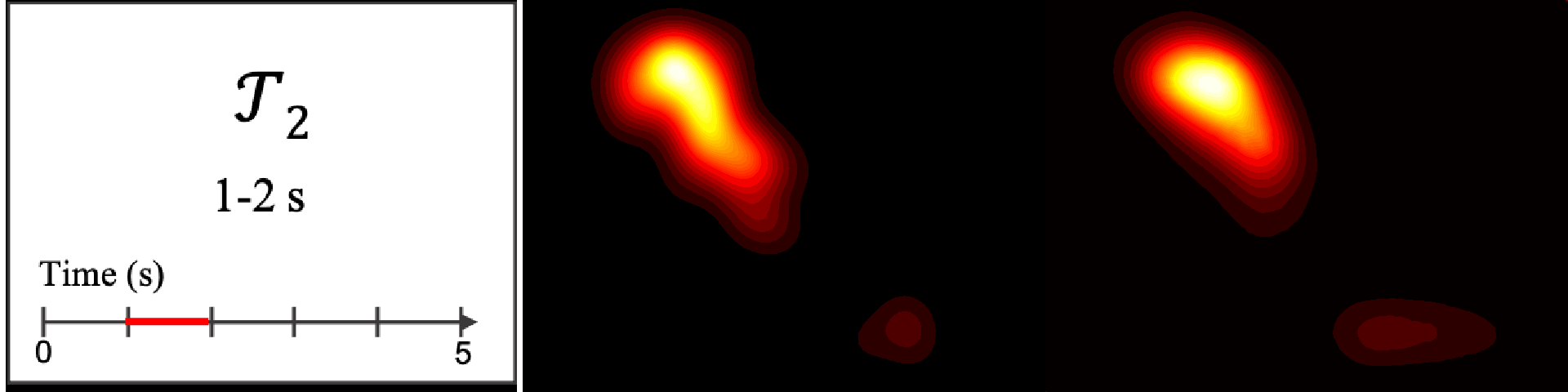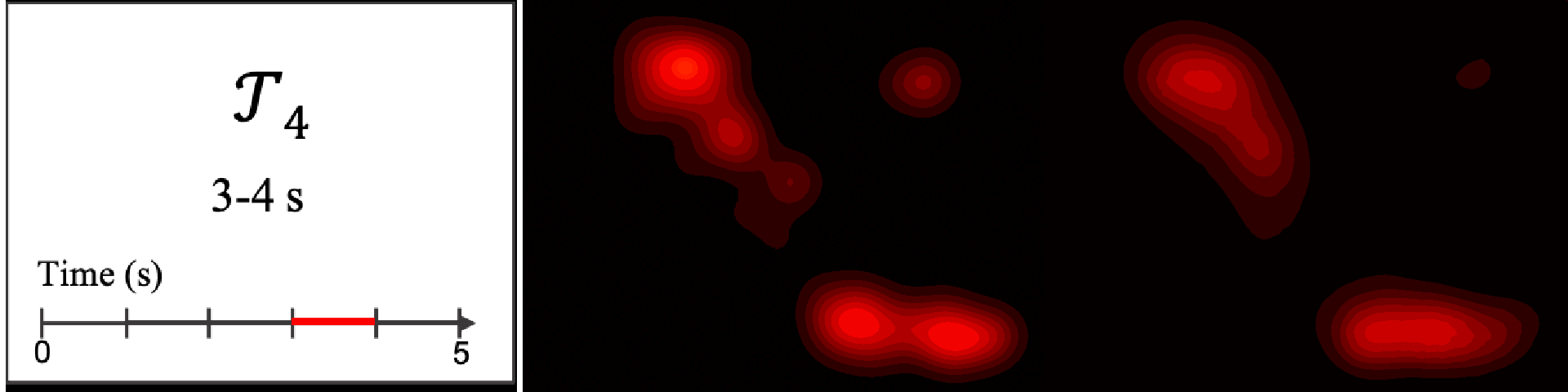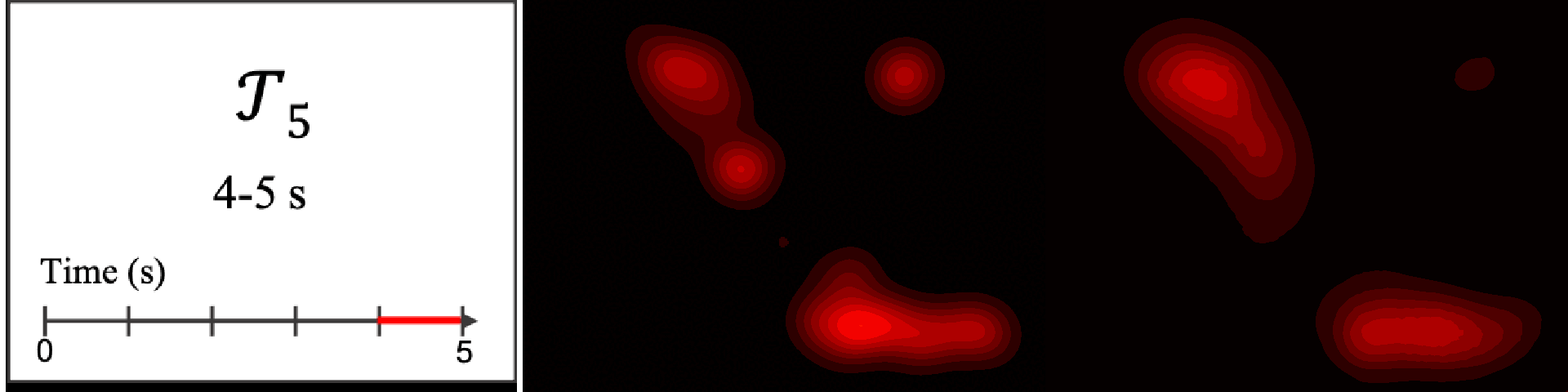
a) Image Saliency
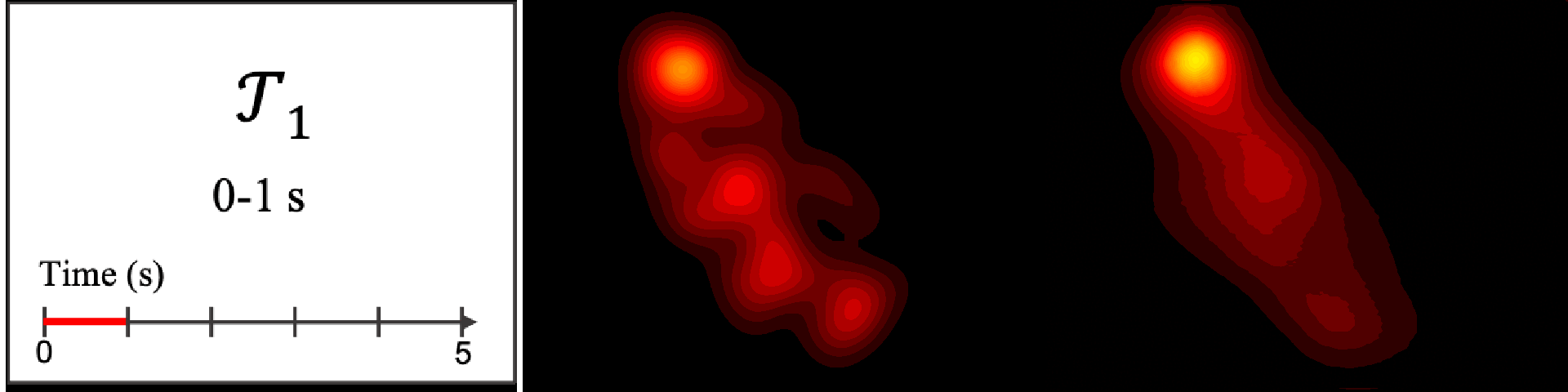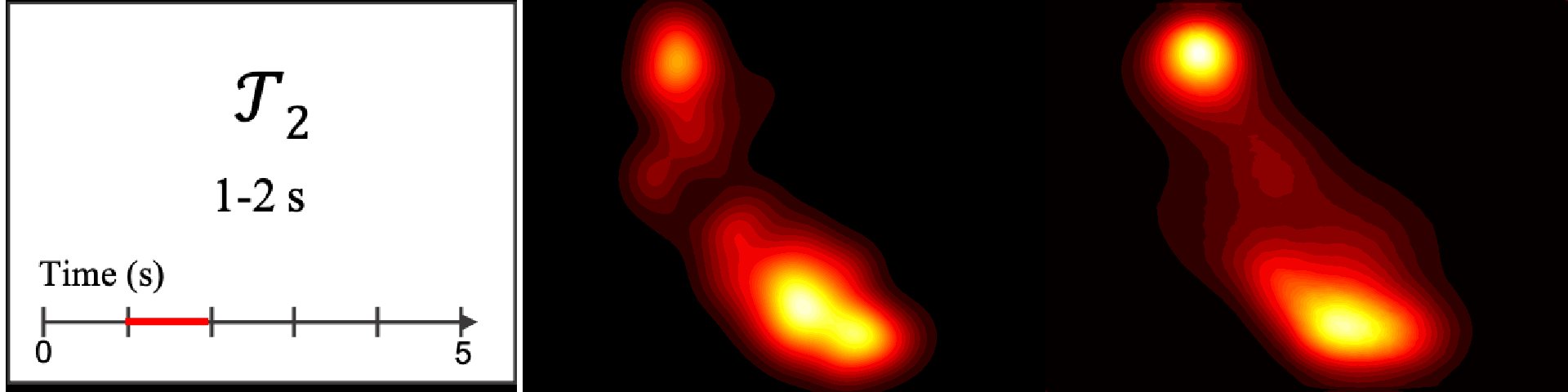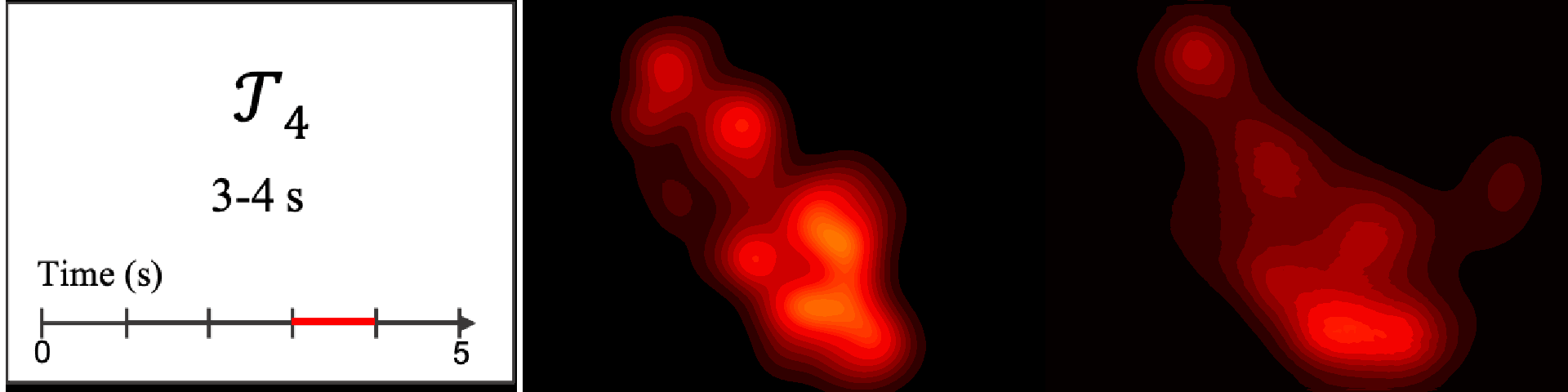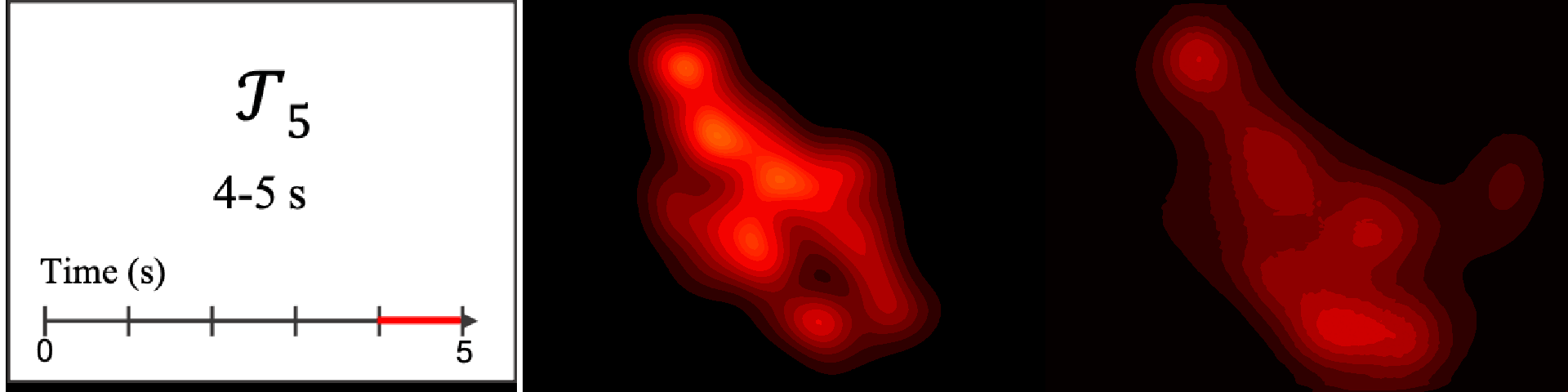
b) Temporal Saliency


c) Image Saliency
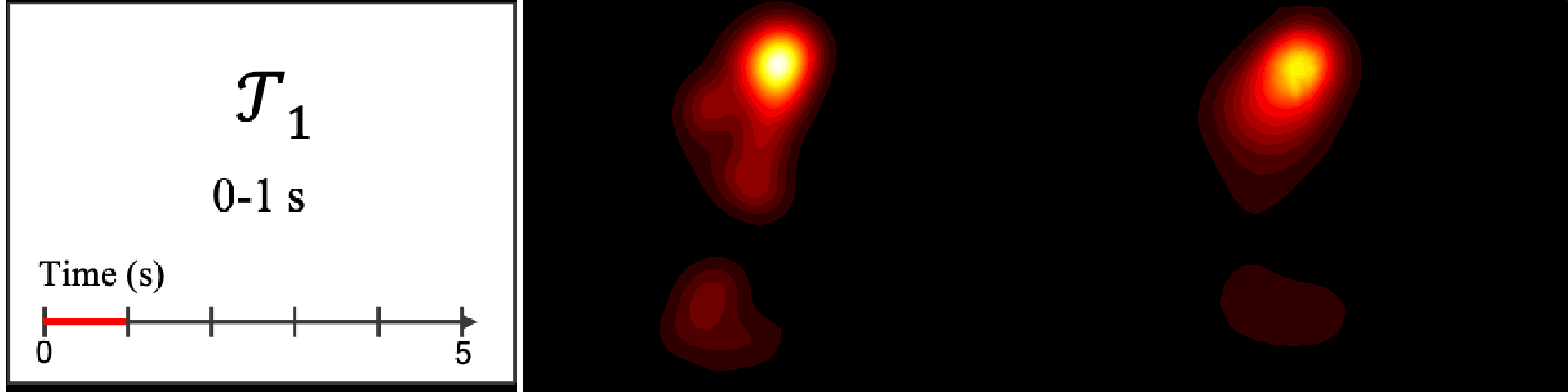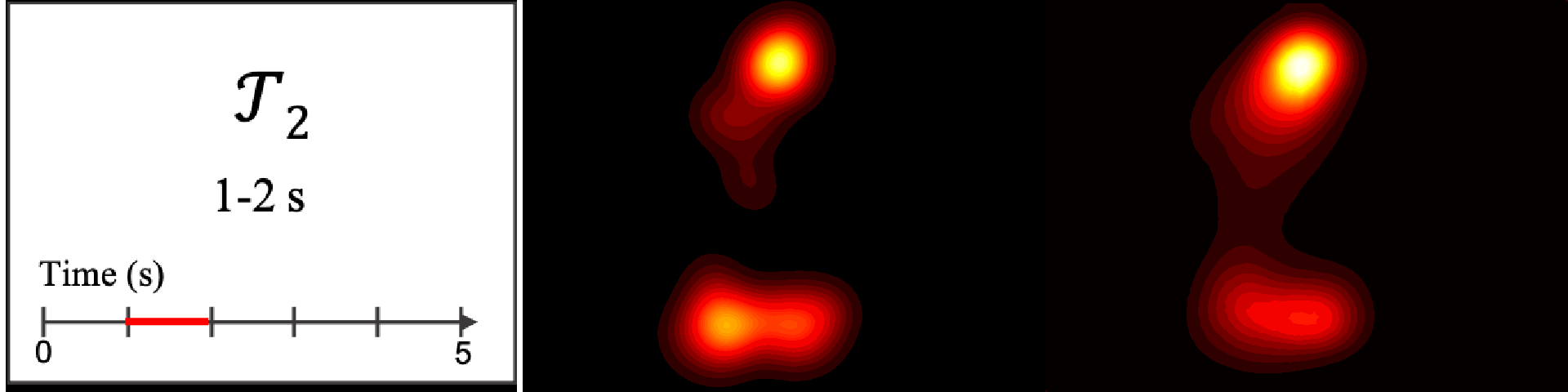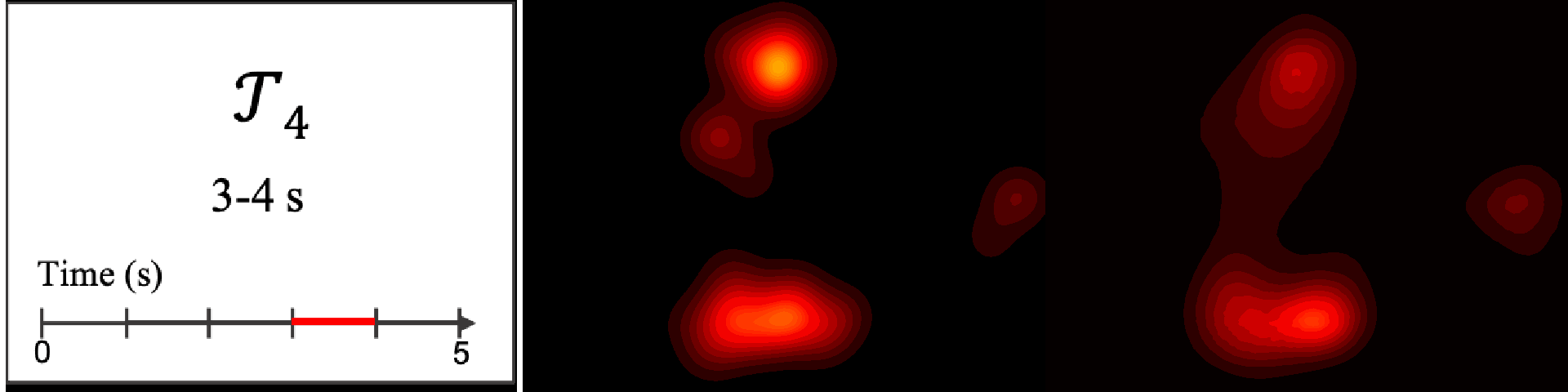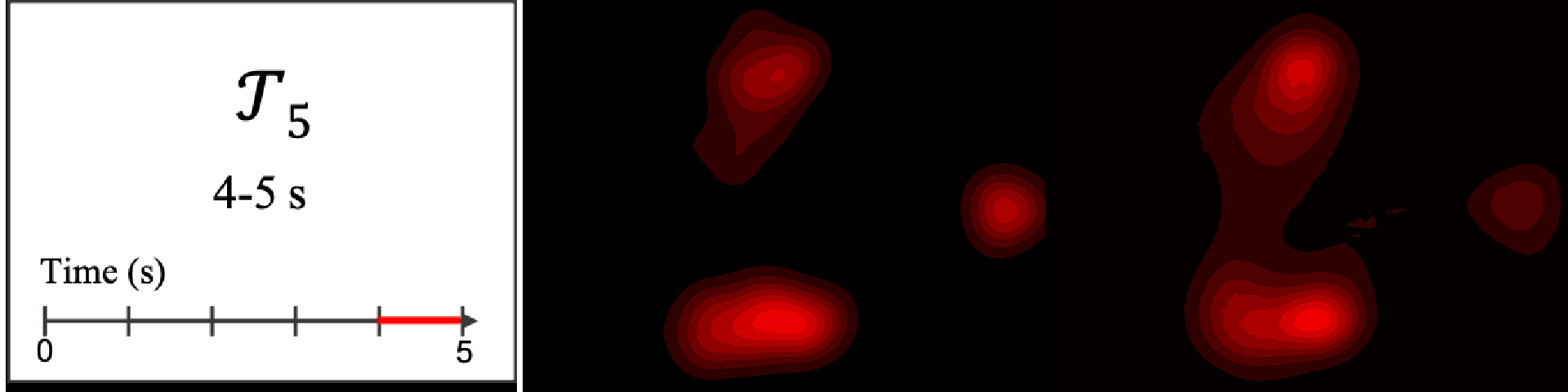
d) Temporal Saliency



e) Image Saliency
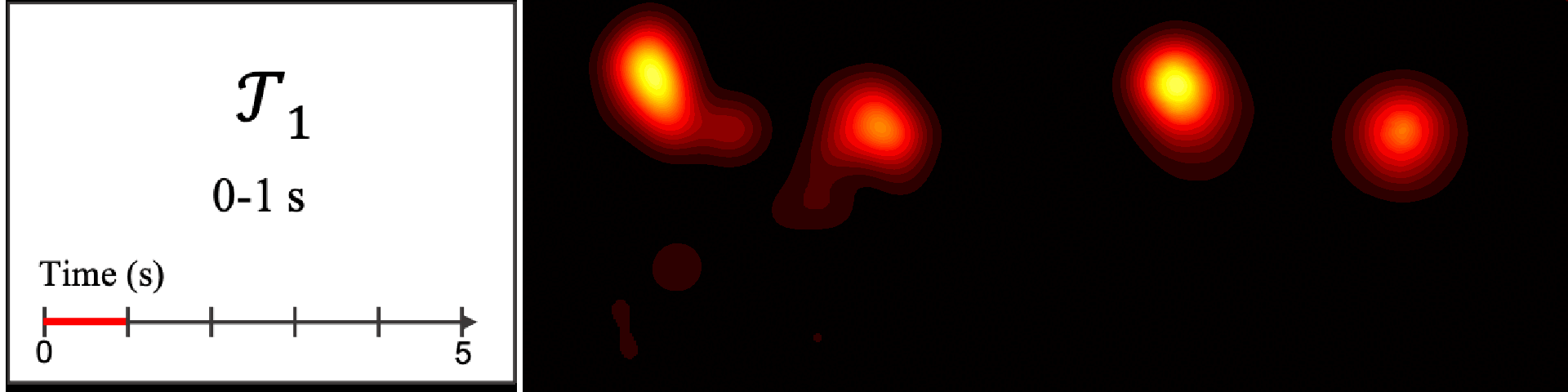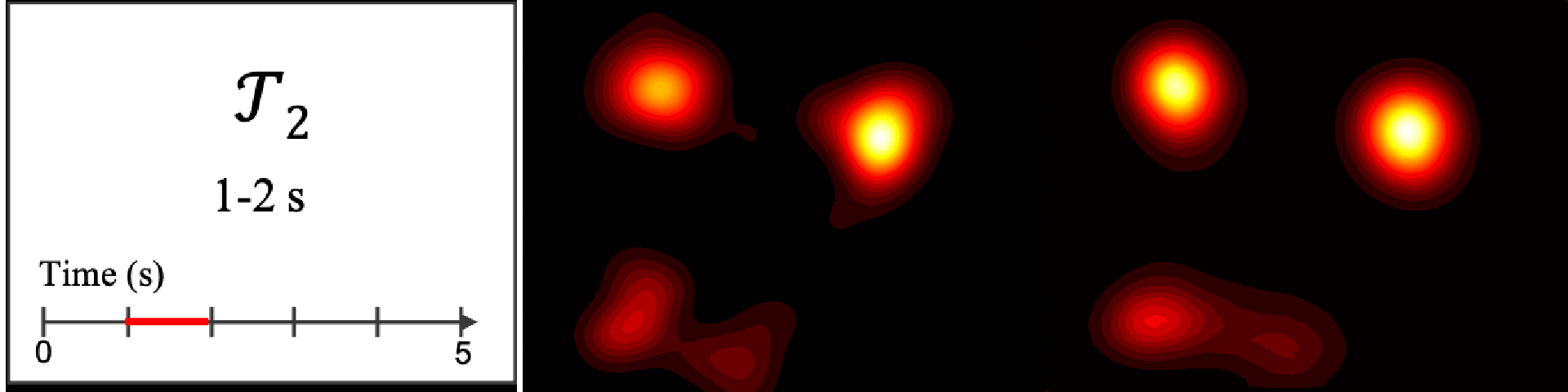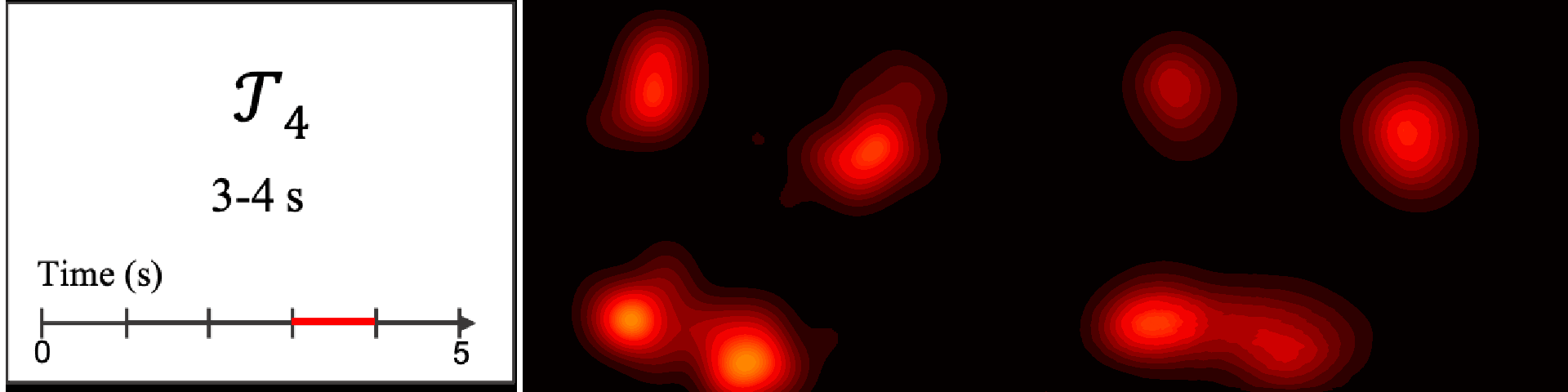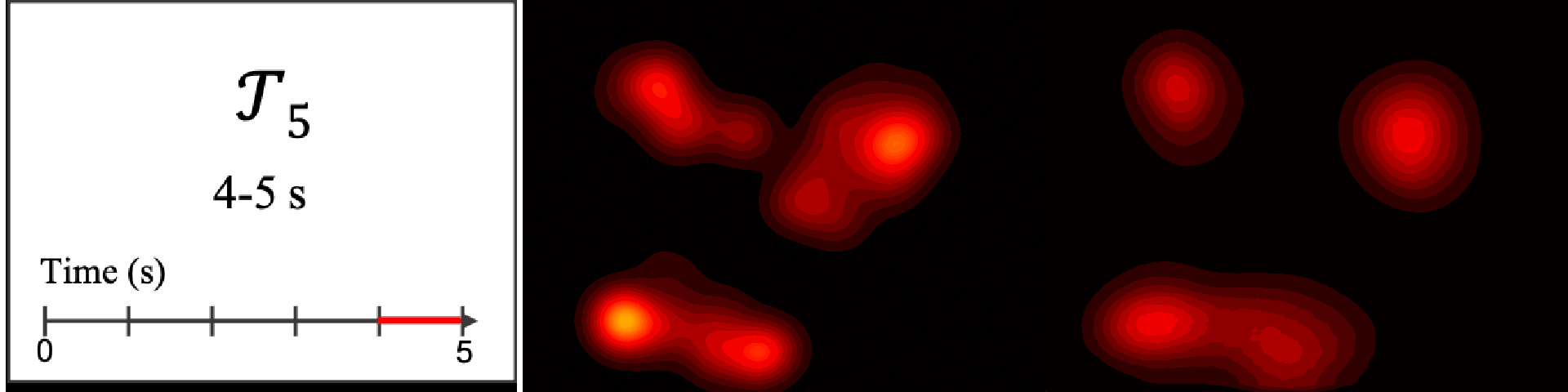
f) Temporal Saliency



g) Image Saliency
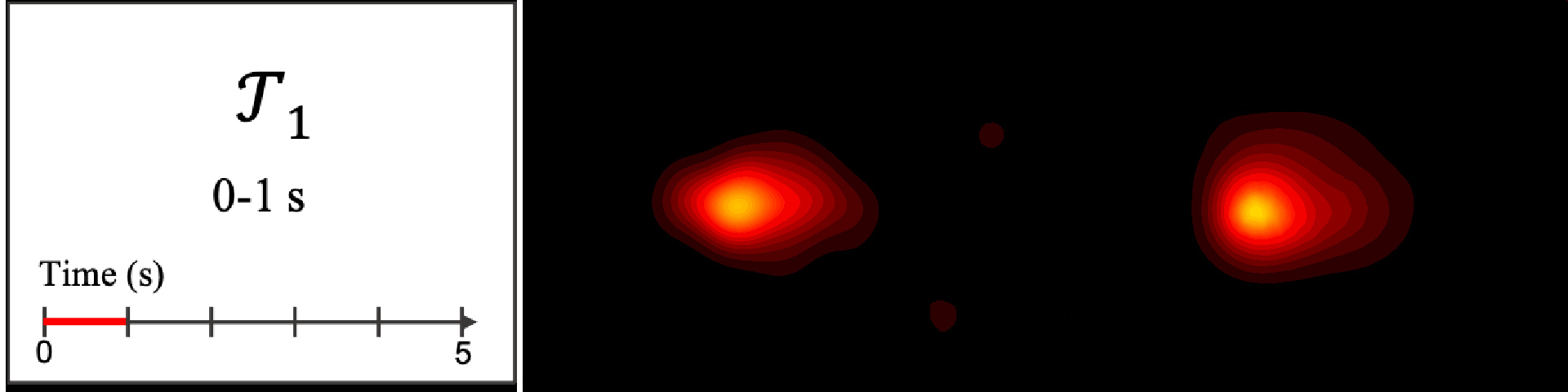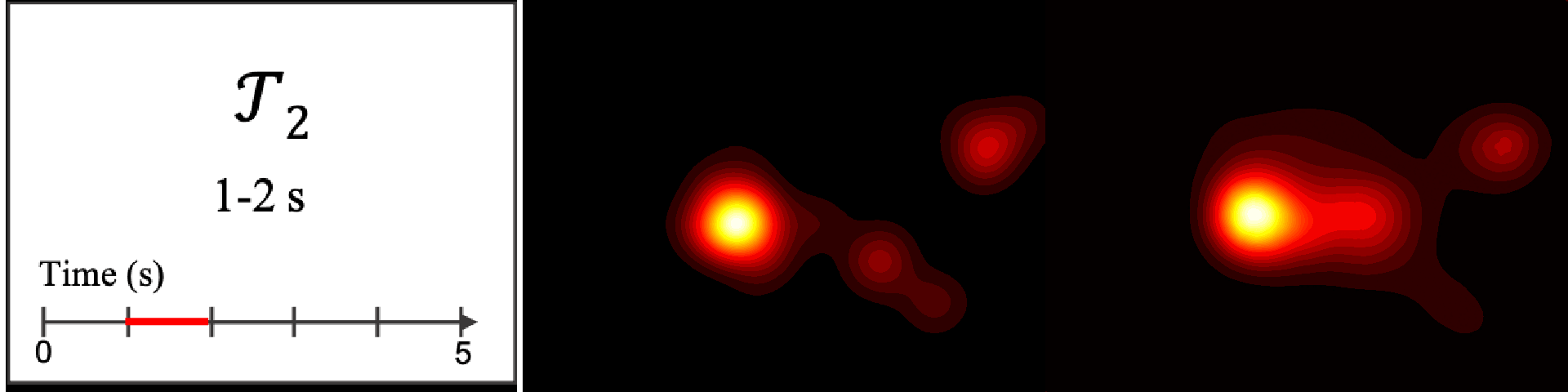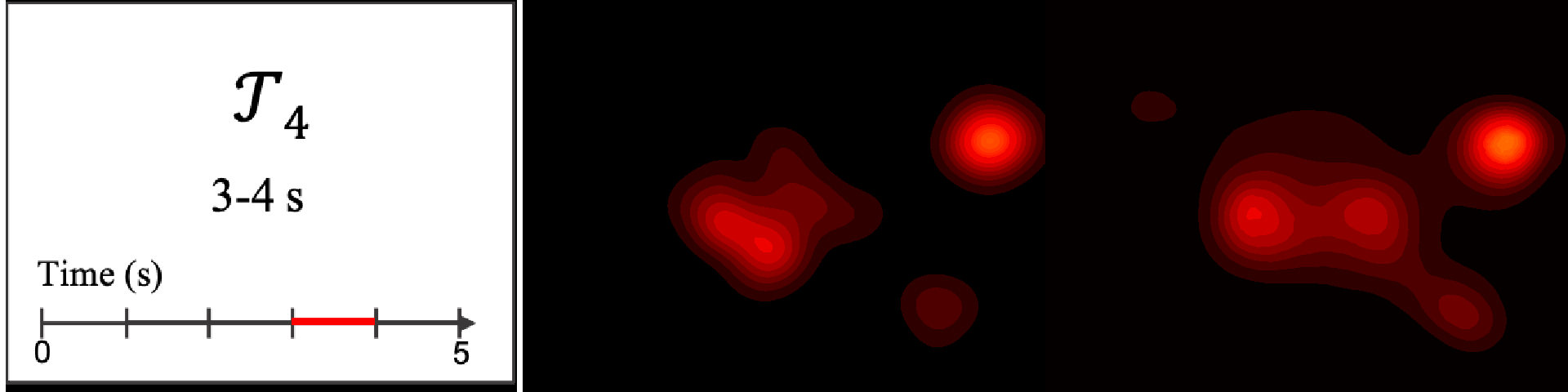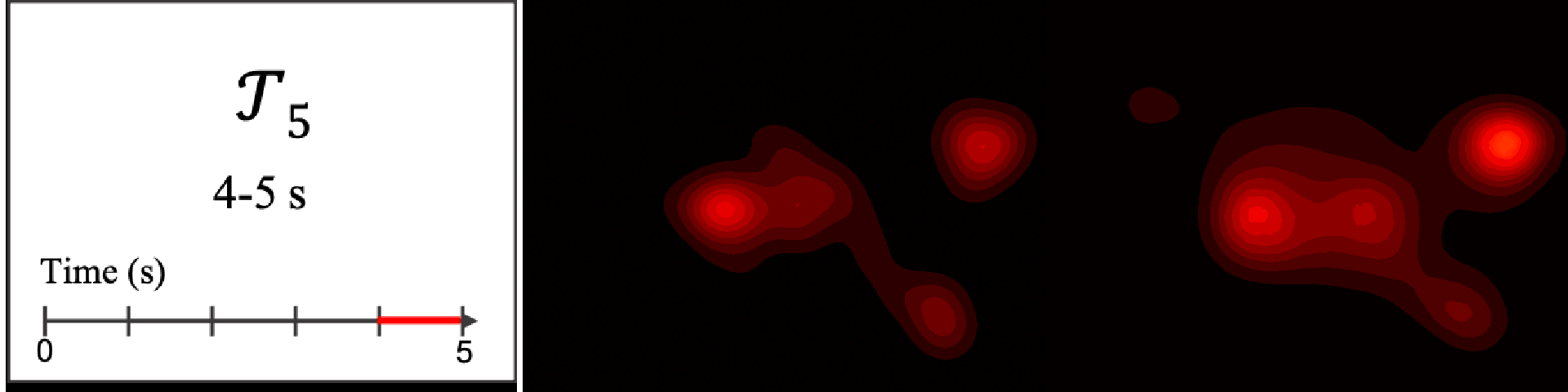
h) Temporal Saliency

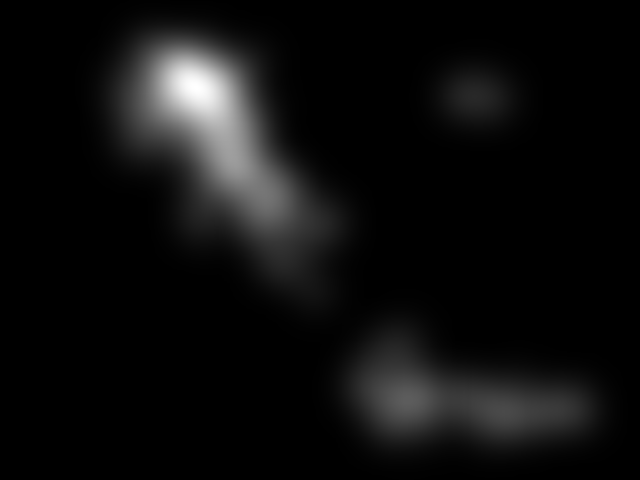

i) Image Saliency
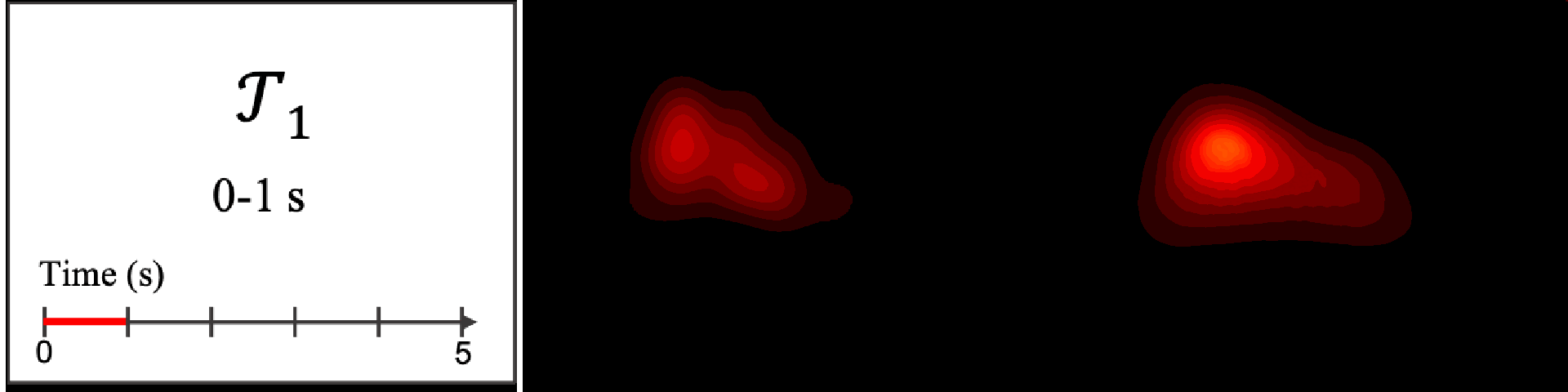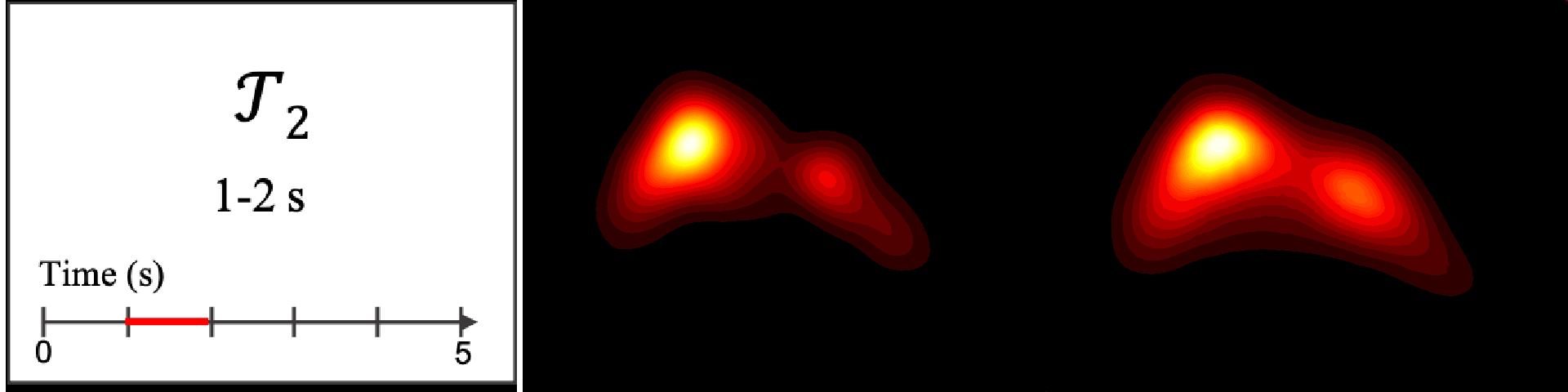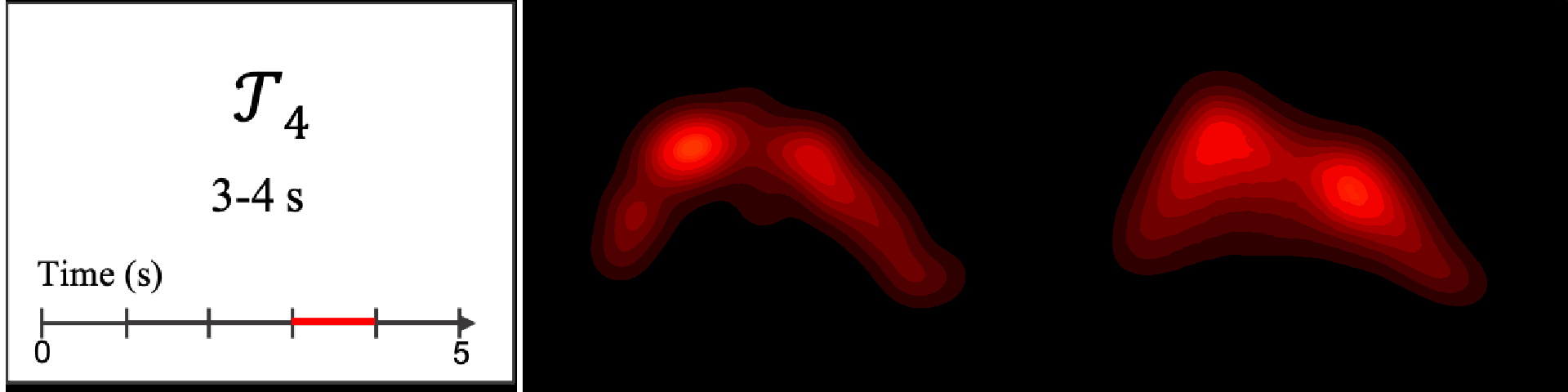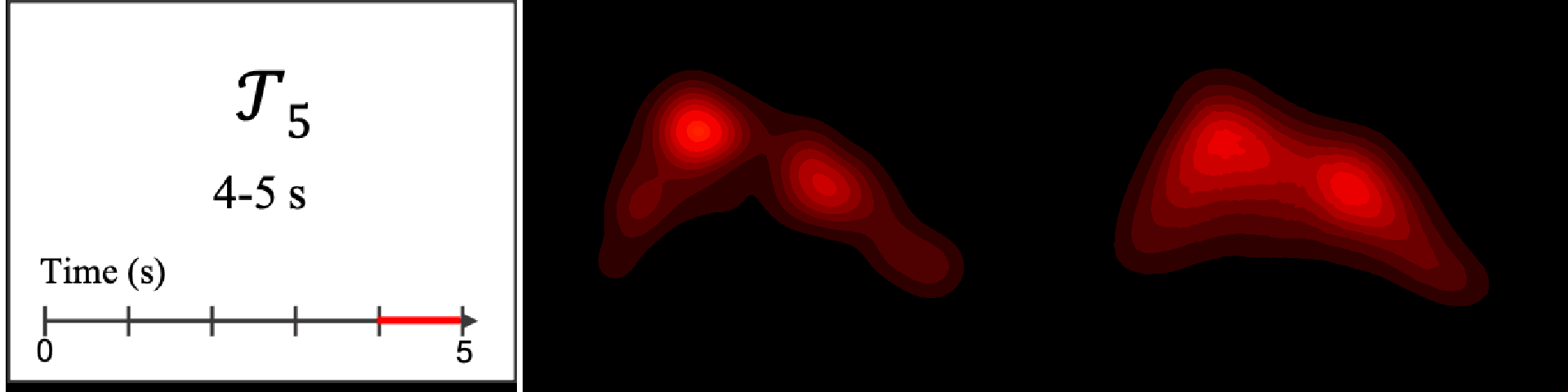
j) Temporal Saliency



k) Image Saliency
l) Temporal Saliency
Figure 8. Image saliency and temporal saliency predictions with their respective ground truths from the SALICON dataset. Black-and-white maps are the image saliency maps for the whole observation duration. Red-yellow maps are the temporal saliency maps for one-second intervals. Our model can predict the temporal saliency of each slice and track attention shifts between regions over time. For input images a) and c), the men are initially salient, then the attention shifts to the inanimate objects. That is, the food and the skateboard become more salient afterwards. In row e), people look at the man on the left first, then at the woman on the right, and eventually at the food. Our model is able to follow these transitions. Similarly, in rows g) and i), the attention is focused on the humans first, then shifts towards the book and the faucet on the right. We are able to capture these shifts in our predictions. In comparison, there are fewer shifts in row l). However, in the first second of observation, the bird on the left is the most salient region in the image, which is also successfully detected by our model.
B. Details on the Statistical Analysis
In this section, we provide details on the calculations presented in Section 3.2 of our paper. We aim to observe the evolution of attention over time and discover temporal patterns in the data.
B.1 Inter-slice similarity across time
$$\mathrm{CC}(\mathcal{T}_j,\mathcal{T}_k) = \frac{1}{N}\sum_{i=0}^{N} \mathrm{CC}(\mathcal{T}_{ij},\mathcal{T}_{ik}) ,\quad j,k \in \{1,\ldots,5\},$$
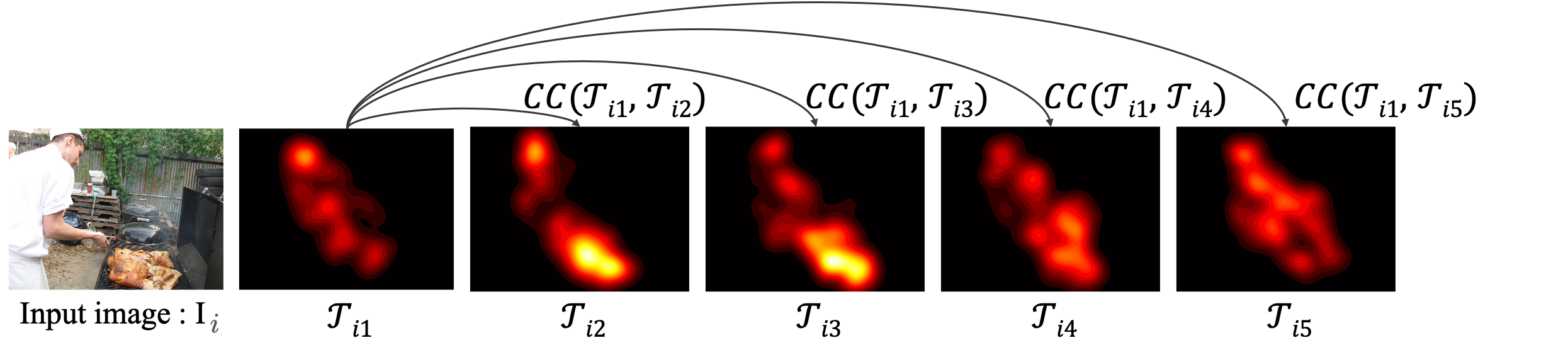

B.2 Intra-slice similarity across images

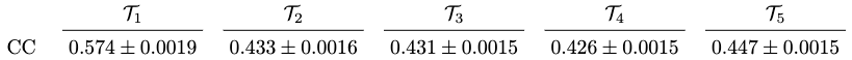
C. Equal Duration vs Equal Distribution
In this section, we describe two slicing alternatives that we introduce in Section 4.1 of our paper. The SALICON dataset contains over 4.9M fixation points distributed across 5 seconds of observation time. Figure 11 shows the distribution of fixations over time.
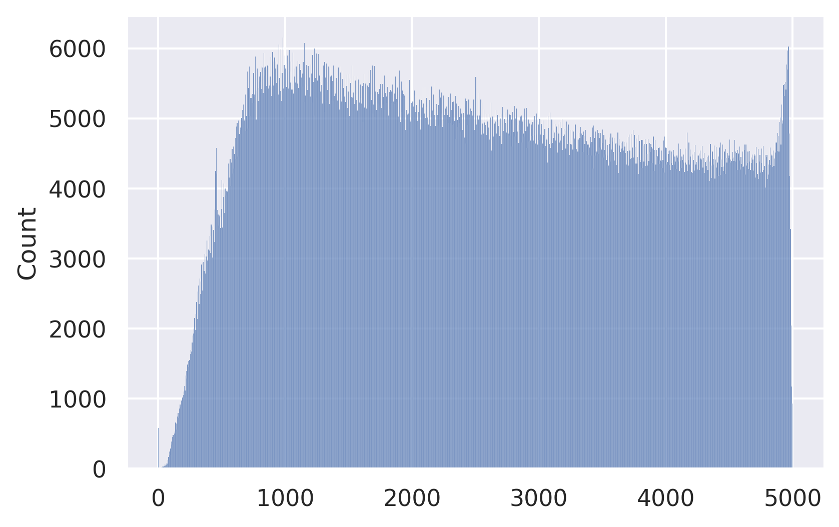
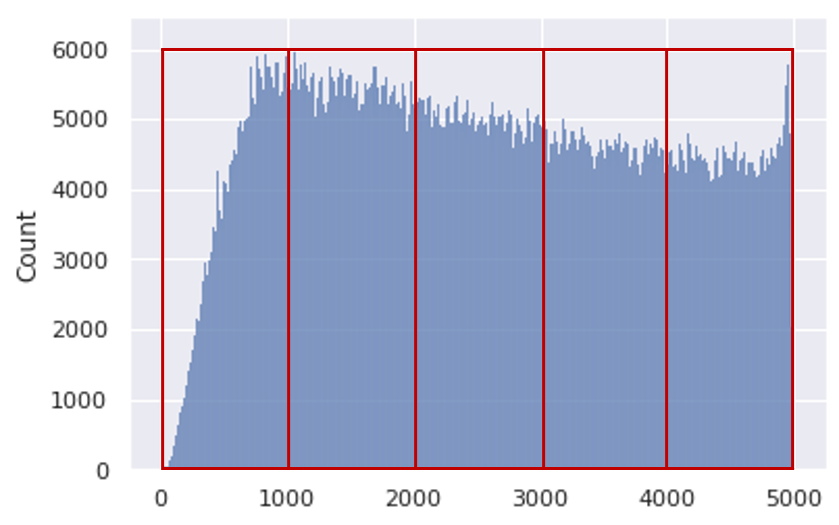
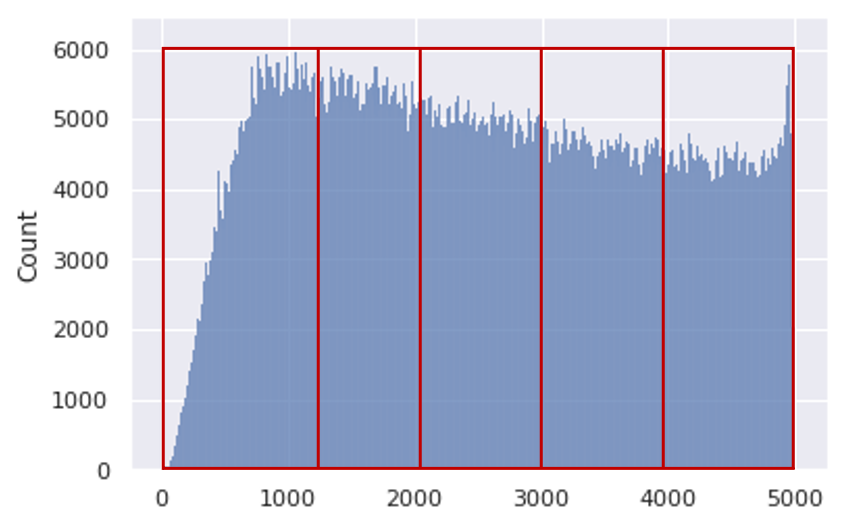
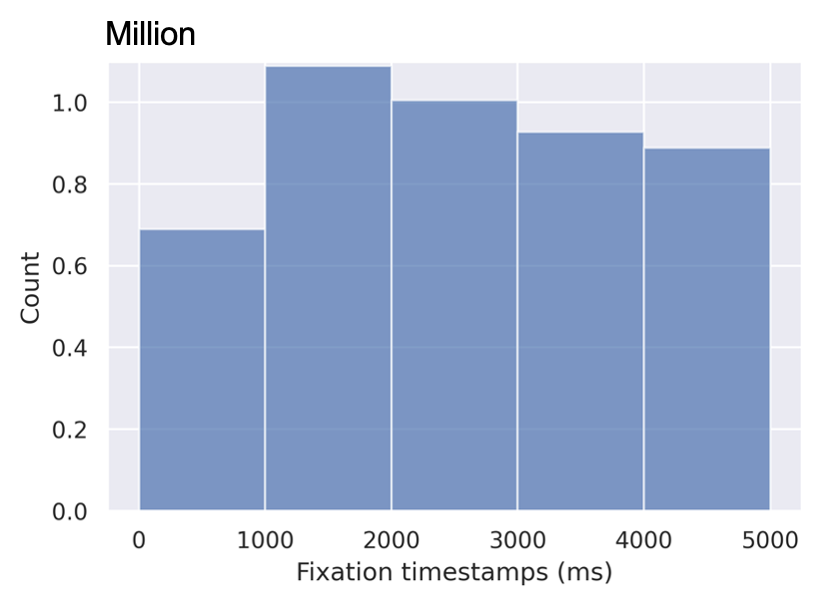
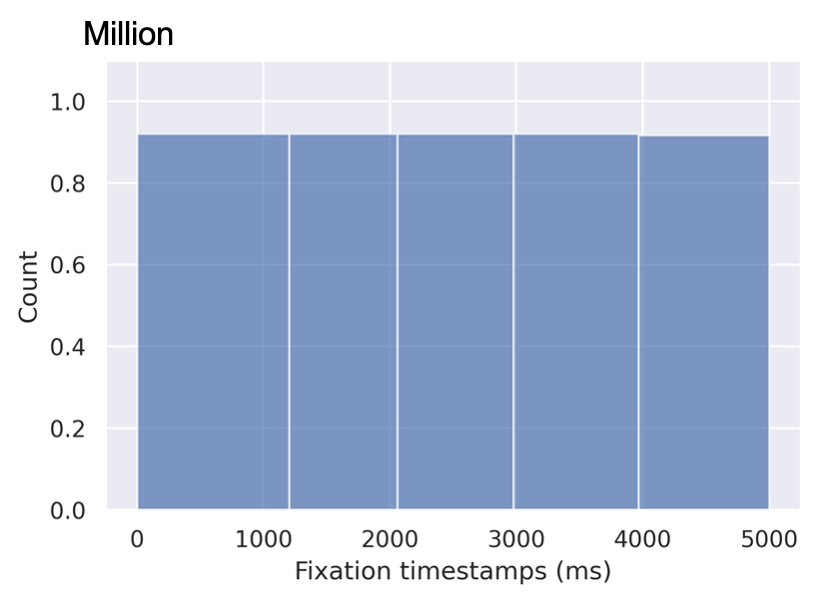
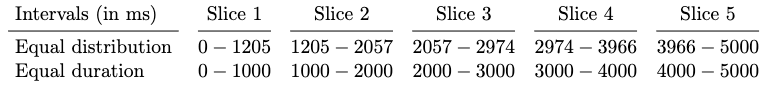


D. Results of the Slicing Alternatives
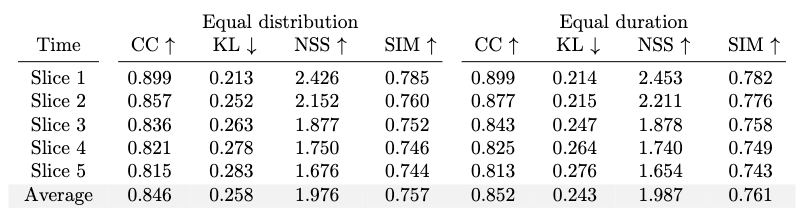
We break down the fixations into time slices with two time-slicing alternatives, namely equal duration and equal distribution as we describe in the previous section. The equal duration method groups the fixations based on their timestamps. Each slice has a different total number of fixations. On the other hand, the equal distribution method groups an equal number of fixations in each slice. Therefore, the duration of each slice is different from that of the other ones. We train and evaluate two models using both sampling methods. The results are presented in Table 13.
E. The Number of Time Slices
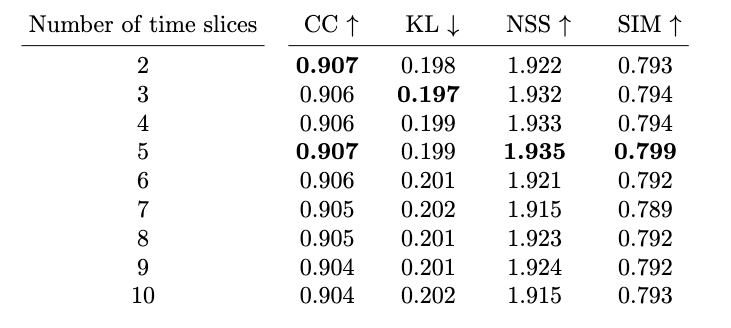
We break down the fixations into different number of time slices as an ablation study as we mention in Section 5.7 of our paper. We train the models using their respective number number of slices and evaluate on image saliency. The results are presented in Table 14.
F. Approximation of Fixation Timestamps
The SALICON dataset provides saliency maps, fixations, and gaze points for each image and observer. Following common practice in eye tracking experiments, Jiang et al.[2] grouped spatially and temporally close gaze points to create fixations. Since these fixations were created by grouping multiple gaze points, they do not have a particular timestamp. SALICON-MD[1] assumes that the fixations are uniformly distributed across the total viewing time. We use a finer approximation for recovering the fixations’ timestamps by minimizing the spatial and temporal distance between a fixation and the nearest gaze point. Here, we provide the details of our approximation.
A simple approach to this problem is to match the raw gaze point in space that is closest to the fixation point. This approach is as follows:
$$f_{t s}=\underset{p_{t s}, \forall p \in \text { GazePoints } }{\operatorname{argmin}}\left\|f_{x y}-p_{x y}\right\|^{2}$$where \(f_{ts}\) is the desired fixation timestamp and \(f_{xy}\) and \(p_{xy}\) are the spatial coordinates of the fixation and gazepoint, respectively. Although this simple spatial attribution has a good matching according to our initial experiments, it does not account for the temporal "boomerang" patterns. The gaze tends to focus first on the most prominent part of the image in a boomerang pattern before investigating the context and returning to the initial attention location [1]. Therefore, this effect produces gaze points close in space but far away in time. To avoid this issue, we used the fact that the fixations are sorted chronologically in the dataset. Assuming a uniform fixation distribution throughout time corresponds to the timestamp assignment \(f_{ts}\) :
$$f_{t s}=5000 * \frac{(\text { index }+1)} {(\text{# of fixations} +1)}$$where total observation time is 5000 milliseconds, index is the fixation's occurrence order, and # of fixations is the total number of fixations in the image. The first method only considers the spatial distance while the second one only considers the temporal distance. Neither of them takes into account all available information. We combine these two approaches for a more accurate spatio-temporal timestamp approximation. For a given fixation, we compute a distance score for each gaze point. We assign the timestamp of the spatially closest gaze point to the given fixation. Then, we calculate \(p_{score}\) as follows, where \(w\) the weighting factor responsible for balancing the difference in time \(p_{time\_diff}\) and distance in space \(p_{space\_dist}\):
$$p_{\text {space}_{-} d i s t}=\left\|f_{x y}-p_{x y}\right\|^{2}$$ $$p_{\text{time}_{-} diff}=\left|p_{t s}- f_{t s}\right| $$ $$p_{\text {score}}=p_{\text{space}_{-}dist}+w * p_{\text {time}_{-}diff}$$ $$f_{t s}=\underset{p_{t s}, \forall p \in \text { GazePoints }}{\operatorname{argmin}} p_{\text {score }}$$where \(p_{t s}\) denotes timestamp of a gazepoint. This requires the optimization of the weighting factor \(w\). Over the 10000 training samples in the SALICON dataset, we emprically found that \(w=\)0.017 is the best weighting factor between spatial and temporal distances.
Back to the top