We propose an end-to-end Multitask Learning Transformer framework, named MulT, to simultaneously learn multiple high-level vision tasks, including depth estimation, semantic segmentation, reshading, surface normal estimation, 2D keypoint detection, and edge detection. Based on the Swin transformer model, our framework encodes the input image into a shared representation and makes predictions for each vision task using task-specific transformer-based decoder heads. At the heart of our approach is a shared attention mechanism modeling the dependencies across the tasks. We evaluate our model on several multitask benchmarks, showing that our MulT framework outperforms both the state-of-the art multitask convolutional neural network models and all the respective single task transformer models. Our experiments further highlight the benefits of sharing attention across all the tasks, and demonstrate that our MulT model is robust and generalizes well to new domains.
Pipeline
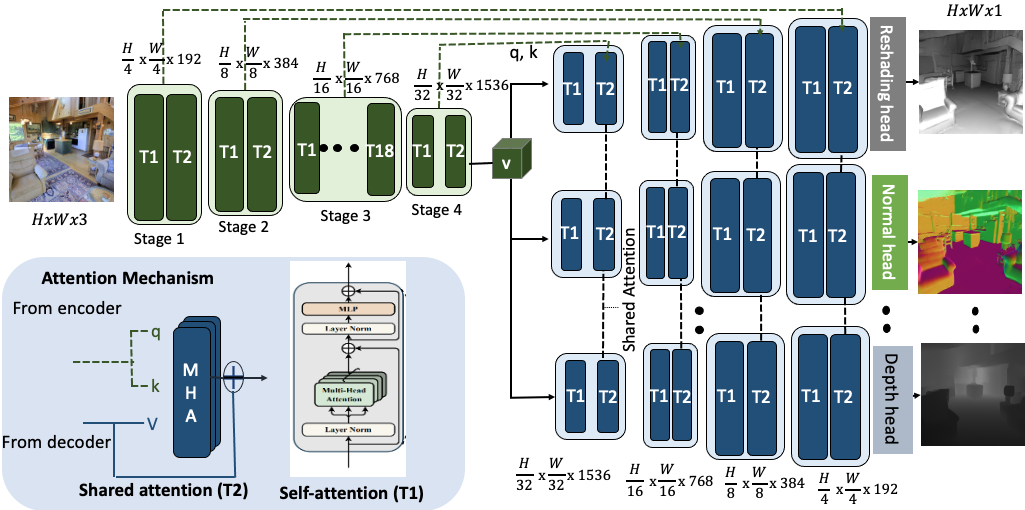
Detailed overview of our MulT architecture. Our MulT model builds upon the Swin transformer backbone and models the dependencies between multiple vision tasks via a shared attention mechanism (shown in the bottom left), which we introduce in this work. The encoder module (in green) embeds a shared representation of the input image, which is then decoded by the transformer decoders (in blue) for the respective tasks. Note that the transformer decoders have the same architecture but different task heads. The overall model is jointly trained in a supervised manner using a weighted loss of all the tasks involved. For clarity, only three tasks are depicted here.
Results

Qualitative comparison on the six vision tasks of the Taskonomy benchmark. From top to bottom, we show qualitative results using CNN multitak learning baselines, such as- MTL, Taskonomy, Taskgrouping, Cross-task consistency; the single-task dedicated Swin transformer and our six-task MulT model. We show, from left to right, the input image, the semantic segmentation results, the depth predictions, the surface normal estimations, the 2D keypoint detections, the 2D edge detections and the reshading results for all the models. All models are jointly trained on the six vision tasks, except for the Swin transformer baseline, which is trained on the independent single tasks. Our MulT model outperforms both the single task Swin baselines and the multitask CNN based baselines. Best seen on screen and zoomed within the yellow circled regions.
Generalization to New Domains
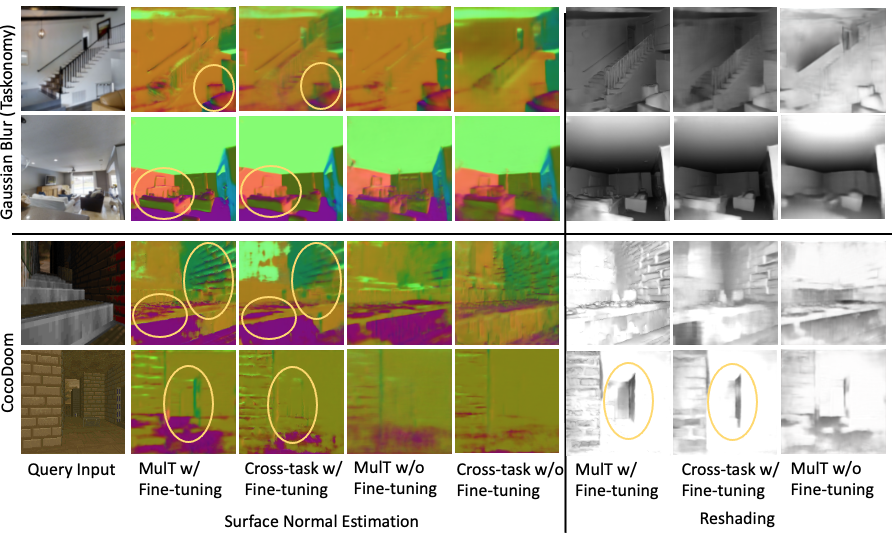
Our MulT model generalizes better to new domains than the Cross-task CNN baseline, both when fine-tuned and not fine-tuned, across the tasks of surface normal prediction and reshading. This shows the benefits of our shared attention module. We test the models on two target domains, Gaussian blur applied to the Taskonomy images and the out-of distribution CocoDoom dataset. Best viewed on screen and when zoomed in the yellow circled regions.